SEPTEMBRE 20, 2023
Découvrez comment créer un puissant système de similarité de texte en moins de 5 minutes avec BigQuery ML et Vertex AI !
Dans le monde du traitement du langage naturel (NLP), mesurer la similarité entre des corpus de texte est une tâche fondamentale. Que ce soit pour identifier des noms de produits similaires, recommander des articles connexes ou faire correspondre des requêtes d'utilisateurs, la recherche de similarité textuelle joue un rôle crucial dans diverses applications. Nous allons explorer comment créer un système simple de recherche de similarité de texte en utilisant l'interface de BigQuery ML avec le modèle d'encodage de texte de Vertex AI.
Les incorporations de texte sont des représentations vectorielles denses de mots ou de phrases qui saisissent les relations sémantiques entre eux. En d'autres termes, des mots ou phrases de significations similaires seront représentés par des vecteurs proches dans un espace à haute dimension. Ces incorporations sont générées grâce à des modèles de langage puissants comme Vertex AI, qui est pré-entraîné sur un large corpus de données textuelles.
Nous allons vous guider à travers le processus de création d'un lien vers Vertex AI et de la configuration du modèle dans BigQuery. Nous commencerons par créer ce lien dans la région multi-région des États-Unis, étant donné que ces modèles sont, pour l'instant, disponibles uniquement dans cette région.
bq --location=us mk \\
--connection \\
--project_id=shikanime-studio-labs \\
--connection_type=CLOUD_RESOURCE \\
vertex_ai
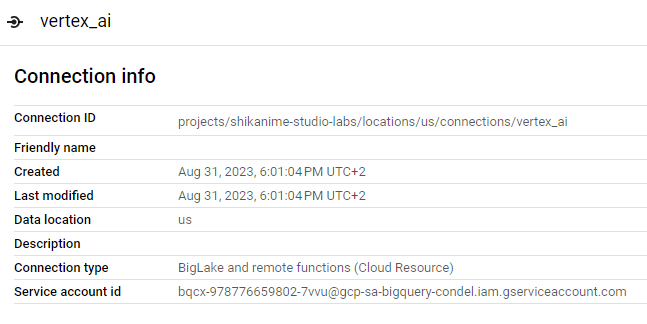
Détail de la connexion Vertex AI
Détail de la connexion Vertex AI
Afin que le service account puisse ensuite appeler l'API Vertex AI, nous devons lui attribuer au moins le rôle Vertex AI User :
gcloud projects add-iam-policy-binding shikanime-studio-labs \\
--member=serviceAccount:bqcx-978776659802-7vvu@gcp-sa-bigquery-condel.iam.gserviceaccount.com \\
--role=roles/aiplatform.user
Ensuite, il nous faudra créer un ensemble de données pour stocker le modèle, ainsi que les différentes tables par la suite :
bq --location=us mk \\
--dataset \\
shikanime-studio-labs:text_search
Ensuite, nous allons procéder à la création du modèle dans BigQuery en utilisant la liaison que nous avons précédemment créée :
CREATE OR REPLACE MODEL
`shikanime-studio-labs.text_search.vertex_ai_text_embedding`
REMOTE WITH CONNECTION `us.vertex_ai`
OPTIONS(REMOTE_SERVICE_TYPE="CLOUD_AI_TEXT_EMBEDDING_MODEL_V1")
Détail du model
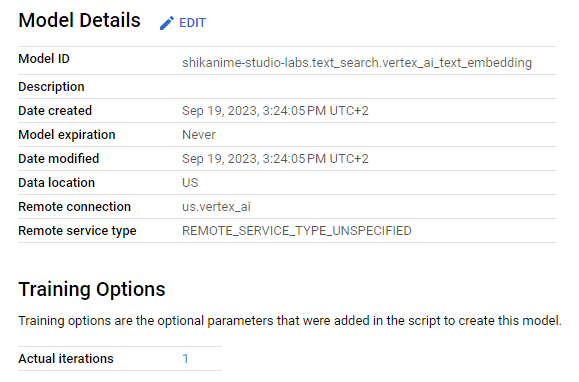
Détail du model
Dans cette section, nous avons mis en place une liaison qui remplit deux fonctions essentielles : elle nous permet d'établir une connexion externe pour interagir avec Google Cloud depuis BigQuery, ce qui implique la création automatique d'un compte de service et la définition des autorisations IAM.
En parallèle, nous avons enregistré le modèle dans BigQuery. Grâce à cette configuration, nous sommes désormais prêts à générer directement des incorporations de texte dans BigQuery, ce qui nous permettra d'effectuer efficacement des recherches de similarité de texte et de mener à bien d'autres tâches liées au traitement du langage naturel.